卷積神經網路(Convolutional neural network,CNN),是一多層的神經網路架構,是以類神經網路實現的深度學習,在許多實際應用上取得優異的成績,尤其在影像物件識別的領域上表現優異。
傳統的多層感知器(Multilayer Perceptron,MLP)可以成功的用來做影像識別,如之前
所介紹,可以用來做MNIST 手寫數字辨識,但是由於多層感知器(Multilayer Perceptron,MLP)在神經元之間採用全連接的方式(Full connectivity),當使用在較高解析度或是較高維度的影像或資料時,便容易發生維度災難而造成過度適合(Overfitting)。
例如,考慮MNIST的手寫輸入資料為28x28解析度,考慮神經元全連接的方式
(Full connectivity),連接到第一個隱藏層神經元便需要28x28=784個權重(Weight)。如果考慮一
RGB三通道色彩圖像輸入,如CIFAR-10為32x32x3的圖像解析度,連接到第一個隱藏層神經
元便需32x32x3=3072個權重(Weight)。那麼如果是200x200x3的圖像解析度,便需要120000
個權重,而這只是連接到隱含層的第一個神經元而已,如果隱含層有多個神經元,那麼連
接權重的數量必然再倍數增加。
像這樣子的網路架構,沒有考慮到原始影像資料各像素(pixel)之間的遠近,或是密集關係,只是一昧的將全部像素(pixel)當各個輸入的特徵值,連接到隱含層神經元,造成爆量增加的權重不僅是一種浪費,因為實際上不須這麼多的權重,效果不僅沒增加,只是增加了運算的負荷,而且很可能會造成過度適合(Overfitting)。而卷積神經網路(Convolutional neural network,
CNN)被提出來後,可以有效的解決此一問題。
事實上卷積神經網路(Convolutional neural network,CNN)設計的目標就是用來處理以多陣列型態表達的資料,如以RGB三通道表達的彩色圖片。CNN和普通神經網路之間的一個實質差別在於,CNN是對原始圖像直接做操作,而傳統神經網路是人為的先對影像提取特徵(例如灰階化,二值化)才做操作。
CNN有三個主要的特點。
1.感知區域(Receptive field):可採用3維的圖像資料(width,height,depth)與神經元連接方式,
實際上也可以直接採用2維的圖像資料,但隱含層內部的神經元只與原本圖像的某一小塊
區域做連結。該區塊我們稱之為感知區域(Receptive field)。
2.局部連結採樣(Local connectivity):根據上述感知區域(Receptive field)的概念,CNN使用過濾
器(filters)增強與該局部圖形空間的相關性,然後堆疊許多這樣子的層,可以達到非線性
濾波的功能,且擴及全域,也就是允許網路架構從原圖小區塊的較好的特徵值代表性,組
合後變成大區塊的特徵值代表性。
3.共享權重(Shared weights):使用的過濾器(filters)是可以重複使用的,當在原始圖像產生一
特徵圖(Feature Map)時,其權重向量(weights vector)及偏誤(bias)是共用的。這樣可以確保
在該卷積層所使用的神經元會偵測相同的特徵。並且即使圖像位置或是有旋轉的狀態,
仍然可以被偵測。
這三個特點使得CNN在圖像辨識上有更好的效果。在實際操作上的三個基礎分別是:
區域感知域(Local Receptive field),卷積(Convolutional ),池化(pooling)。
我們可以從下面圖形化的實際操作來理解它的意思。
卷積層(Convolutional Layer )
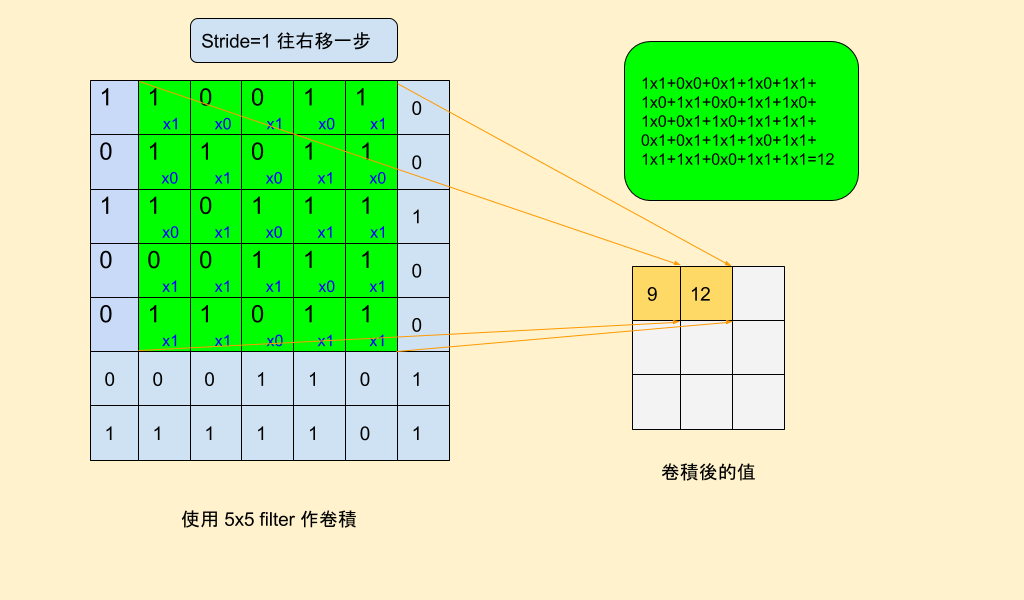
下圖1,2說明在卷積層的運作方式,假設原始影像為一32x32x3維度,我們可以任意給定一
卷積核(filter),其卷積核的值即為權重(weight)。其大小可以為5x5x3,3為與原影像有一樣的深度(RGB三通道),如果輸入影像為一灰階單通道色彩,那麼卷積核大小5x5即可。卷積核大小3x3或5x5或7x7...等等可以自訂,通常為奇數維度。
接著與原圖像相同的小區域計算點積,得到的一個值便是在新的feature Map的一個新元素值。卷積核會在原始的圖像或者前一個圖像(Map)按照Stride(步伐)的設定移動,直到掃描完全部圖像區域,這樣便會產生一個新的Feature Map。便是下圖圖3~圖5所示,在這個步驟中產生單一新feature Map所使用的權重W,也就是卷積核是共用的,並且共用同一個偏誤(bias),通常初始預設偏誤(bias)可以為0。這樣確保這一新的feature map偵測的是該原始圖像同一特徵。
<圖1>

<圖2>



這邊要注意,上圖3~5只是單純說明當卷積操作時如何作點積取和,實際在CNN神經網路運算裡,產生的新Feature Map裡的單一元素便是連接到一個神經元做運算,故其運算應當如下公式,這就是一般神經網路向前傳遞的公式形式:

W便是kxk維卷積核,Xij為前一個圖像的元素值,i,j為其index。
b為偏誤(bias) 預設可以為0。
S()為一激勵函數可以為Sgmoid或ReLu或其他函數,如下圖7。
y為輸出的值,便是產生一新feature Map上其中的一個元素值。
也就是說卷積層的每一個feature map是不同的卷積核在前一層圖像(map)上作卷積並將對應元素
累加後加一個偏誤(bias),再使用激勵函數如sigmod得到的。
另外要注意的是,卷積層要產生幾個新的feature map個數是在網路架構初始化指定的,而要產生幾個新的feature Map,便要使用相同數量的不同卷積核。例如下圖8及圖9所示,使用
6個不同的卷積核便可產生6個feature Map。
而feature map的大小是由卷積核和上一層輸入圖像的大小決定的,假設上一層的圖像大小是n*n、卷積核的大小是k*k,則該層的feature map大小是(n-k+1)*(n-k+1),比如上圖3~5,從7*7的圖像大小,產生3x3 feature map (3=7-5+1),當然這是在預設stride=1的情狀下。
也就是說卷積層的每一個feature map是不同的卷積核在前一層圖像(map)上作卷積並將對應元素
累加後加一個偏誤(bias),再使用激勵函數如sigmod得到的。
另外要注意的是,卷積層要產生幾個新的feature map個數是在網路架構初始化指定的,而要產生幾個新的feature Map,便要使用相同數量的不同卷積核。例如下圖8及圖9所示,使用
6個不同的卷積核便可產生6個feature Map。
而feature map的大小是由卷積核和上一層輸入圖像的大小決定的,假設上一層的圖像大小是n*n、卷積核的大小是k*k,則該層的feature map大小是(n-k+1)*(n-k+1),比如上圖3~5,從7*7的圖像大小,產生3x3 feature map (3=7-5+1),當然這是在預設stride=1的情狀下。

<圖7>常見激勵函數

<圖8>使用第二個不同的卷積核(Filter)產生第二個feature map

至此,我們來以下圖9計算一下使用了多少參數(w權重及b偏誤),及多少連接到神經元。
原始圖像大小為32x32,使用6個不同的5x5 卷積核(filter),產生了6個新feature map。
產生的新featue map大小為28x28,因為32-5+1=28
一個新feature map所使用參數數量為:5x5+1=26,也就是5x5個W權重及1個偏誤(bias)
6個新feature map所使用參數數量為:6x(5x5+1)=156個參數
那麼一個新feature map所須連接數量為:(5x5+1)x28x28=20384,也就是28x28個神經元各有(5x5+1)個權重及偏誤連接。
那麼6個新feature map所須連接數量為(5x5+1)x28x28x6=122304。
這個連接方式及數量其實便是LetNet-5第一個卷積層的狀況。
有關卷積(Convolutional)的操作也可以參閱底下一般影像處理領域的操作。其操作本質上便
是對影像作濾波(filter)
OPENCV(7)--2D Convolution ,Image Filtering and Blurring (旋積,濾波與模糊)
另外使用不同的卷積核(kernel filter),便是對影像作處理找出影像特徵,如找出"邊","角點"。
OPENCV(9)--Image Gradients(圖像梯度)
<圖9>使用6個不同的卷積核(Filter),產生6個feature map

底下圖10是用來說明不同的Stride設定,在卷積後,所產生的新Map尺寸便會不同。
例如原本圖像為7x7(N=7),而且卷積核為3x3(F=3),那麼當sride=1時,所卷積後所產生的新圖
像大小為5x5,計算方式(7-3)/1+1=5,如果stirde改成2,那麼新產生的圖像大小為3x3,計算方式為(7-3)/2+1=3。
<圖10>

底下圖11說明Padding的作法,原本的圖像在經過卷積後,原本的大小必然會縮小,如原本7x7經由卷積核3x3及stride=1,卷積後變成了5x5大小。那麼如何保持卷積後大小還能不變呢?
便是可以使用Padding的方式,Zero Pad便是先在原始圖像外圍先補0(注意一般在電腦圖像計算裡數值0代表黑色,這也就是會產生黑框),那麼原本7x7影像便會成為9x9大小,這時再作卷積,(9-3)+1=7,便還是可以得到7x7原本的大小。
有關Pading的方式除了外圍補0外也可以補1(如果是二值化影像便是白邊),也可以補跟他相鄰元素一樣的值。其相關操作在一般的影像處理書籍或資料皆有相關說明,可再自行參閱。
<圖11>

池化層(Pooling Layer)
池化層緊接在卷積層之後,是將前一層的輸入資訊作壓縮。池化通常使用2x2核並且stride=2
進行卷積。可以使用均值方式計算,但通常使用取最大值為較為普遍的作法,稱之為Max Pooling.如下圖12,13。下圖12原本為28x28圖像,經Pooling 後大小變為14x14,下圖13解釋了其
Max pooling的操作方式。另外通常在這一層不再作計算權重及偏誤以及激勵函數。只單純Max pooling。


CNN神經網路架構,最後仍有全連接層(Fully connected Layer),其操作其運算方式便如同一般的MLP方式。整個CNN神經網路仍然使用BP反向傳遞演算法計算誤差後更新權重。
<圖14>全連接層

底下我們簡單實作一個簡單的CNN網路,使用MNIST數據集,並使用Tensorflow來實現。
實際程式使用Python3.5及Tensorflow R1.0.1在win10環境。
首先如下圖15,我們自訂一個CNN架構,在這個架構裡,C1,C3的卷積層使用Padding的技術,故卷積後,尺寸大小不變。S2,及S4為pooling層,F5為一個1024神經元與S4作全連接,最後輸出10 個數字類別的可能機率。
在Tensorflow 理定義padding='SAME',如下程式在卷積層會自動使用padding成一樣尺寸。
def conv2d(img, w, b):
return tf.nn.relu(tf.nn.bias_add\
(tf.nn.conv2d(img, w,\
strides=[1, 1, 1, 1],\
padding='SAME'),b))
<圖15>自訂一個CNN網路架構

底下為程式初始參數設定,及簡單的解釋主要程式。
# Parameters
learning_rate = 0.001
training_iters = 400000 #迭帶400000次
batch_size = 128 #使用minibatch方式
display_step = 10
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
#原本MNIST數據集為1x784,會被reshape回28x28,當作原始輸入
n_classes = 10 # MNIST total classes (0-9 digits)
dropout = 0.75 # Dropout, probability to keep units
#dropout = 0.75意義為:為了減少過度適合(Overfitting)的問題,應用了丟棄(dropout)正則化技術。
#意旨在神經網路中丟棄一些連接的單元(輸入,隱藏,和輸出),決定丟棄那些神經元是隨機
#的也可以用機率決定。
wc1 = tf.Variable(tf.random_normal([5, 5, 1, 32])) # 5x5 conv, 1 input, 32 outputs
#32代表第1個卷積層要產生32個新的feature map
wc2 = tf.Variable(tf.random_normal([5, 5, 32, 64])) # 5x5 conv, 32 inputs, 64 outputs
#64代表第2個卷積層要產生64個新的feature map
#5,5則是5x5的卷積核(filter權重)
wd1 = tf.Variable(tf.random_normal([7*7*64, 1024])) # fully connected, 7*7*64 inputs, 1024 outputs
wout = tf.Variable(tf.random_normal([1024, n_classes])) # 1024 inputs, 10 outputs (class prediction)
#1024則是全連接層的1024個神經元數量,n_classes=10,代表0-9的數字類別
# Convolution Layer
conv1 = conv2d(_X,wc1,bc1)
conv1 = max_pool(conv1, k=2)
conv1 = tf.nn.dropout(conv1,keep_prob)
#定義第1層卷積層及pooling層並使用dropout正則化
# Convolution Layer
conv2 = conv2d(conv1,wc2,bc2)
conv2 = max_pool(conv2, k=2)
conv2 = tf.nn.dropout(conv2, keep_prob)
#定義第2層卷積層及pooling層並使用dropout正則化
# Fully connected layer
dense1 = tf.reshape(conv2, [-1, wd1.get_shape().as_list()[0]]) # Reshape conv2 output to fit dense layer input
dense1 = tf.nn.relu(tf.add(tf.matmul(dense1, wd1),bd1)) # Relu activation
dense1 = tf.nn.dropout(dense1, keep_prob) # Apply Dropout
#定義F5層全連接層使用ReLu激勵函數及dropout正則化
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=pred))
#計算成本函數的方式並使用softmax_cross_entropy_with_logits
#注意,在Tensorflow R1.0.1版,注意這兩個參數(labels=y, logits=pred)的放法跟以前版本不同
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
#使用AdamOptimizer最佳化。
<圖16>底下為訓練結果及測試結果

<完整程式>
加入阿布拉機的3D列印與機器人的FB專頁
https://www.facebook.com/arbu00/
[1]書名:深度學習快速入門,作者:Giancarlo Zaccone 傅運文譯
[3]CS231n Convolutional Neural Networks for Visual Recognition Table of Contents: Architecture Overview
<其他相關文章>
人工神經網路(1)--使用Python實作perceptron(感知器)
人工神經網路(2)--使用Python實作後向傳遞神經網路演算法(Backprogation artificial neature network)
深度學習(1)-如何在windows安裝Theano +Keras +Tensorflow並使用GPU加速訓練神經網路
機器學習(1)--使用OPENCV KNN實作手寫辨識
機器學習(2)--使用OPENCV SVM實作手寫辨識
演算法(1)--蒙地卡羅法求圓周率及橢圓面積(Monte carlo)
機器學習(3)--適應線性神經元與梯度下降法(Adaline neuron and Gradient descent)
機器學習(4)--資料標準常態化與隨機梯度下降法( standardization & Stochastic Gradient descent)
機器學習(5)--邏輯斯迴歸,過度適合與正規化( Logistic regression,overfitting and regularization)
機器學習(6)--主成分分析(Principal component analysis,PCA)
機器學習(7)--利用核主成分分析(Kernel PCA)處理非線性對應
機器學習(8)--實作多層感知器(Multilayer Perceptron,MLP)手寫數字辨識